服务热线
400-630-8958服务热线
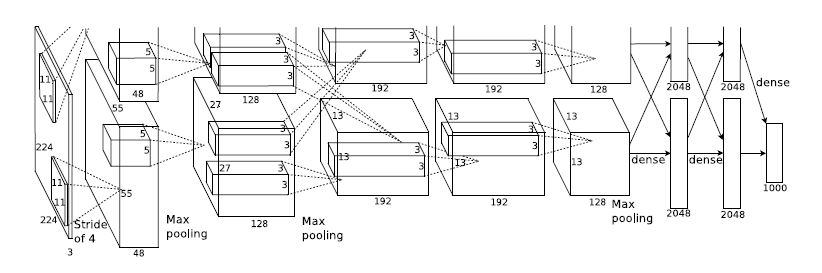
400-630-8958卷积,是卷积神经网络中最重要的组件之一。不同的卷积结构有着不一样的功能,但本质上都是用于提取特征。比如,在传统图像处理中,人们通过设定不同的算子来提取诸如边缘、水平、垂直等固定的特征。而在卷积神经网络中,仅需要随机初始化一个固定卷积核大小的滤波器,并通过诸如反向传播的技术来实现卷积核参数的自动更新即可。其中,浅层的滤波器对诸如点、线、面等底层特征比较敏感,深层的滤波器则能够适用于提取更加抽象的高级语义特征,以完成从低级特征到高级特征的映射。本文将从背景、原理、特性及改进四个维度分别梳理10篇影响力深远的经典卷积模块以及10篇有代表性的卷积变体,使读者对卷积的发展脉络有一个更加清晰的认知。
CNNs中的卷积,也称为滤波器,是由一组具有固定窗口大小且带可学习参数(learnable paramerters)的卷积核所组成,可用于提取特征。
如下图所示,卷积的过程是通过滑动窗口从上到下,从左到右对输入特征图进行遍历,每次遍历的结果为相应位置元素的加权求和:
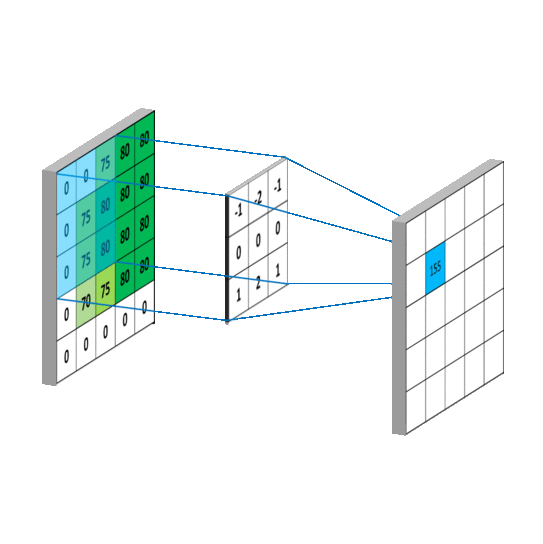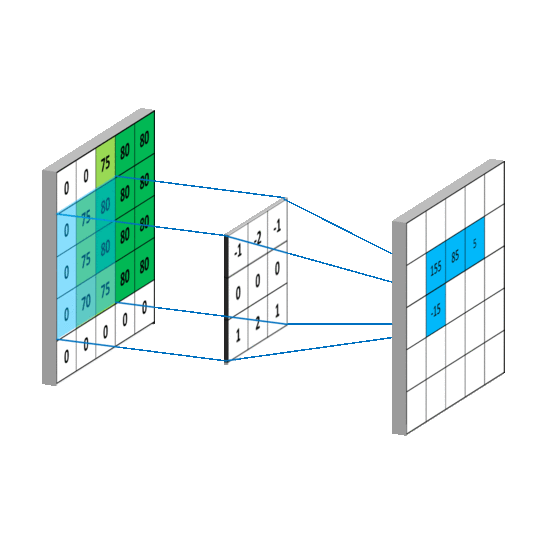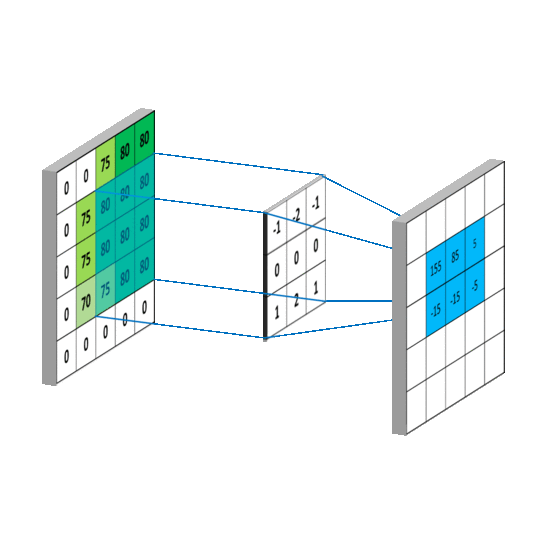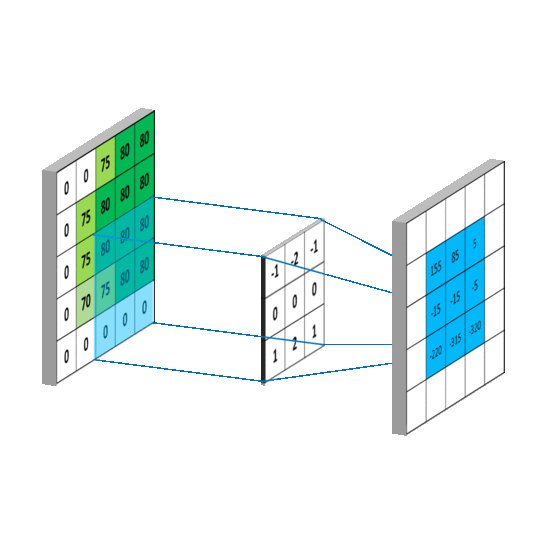
传统的神经网络层使用矩阵乘法,由一个参数矩阵和一个单独的参数描述每个输入和每个输出之间的交互,即每个输出单元与每个输入单元进行密集交互。
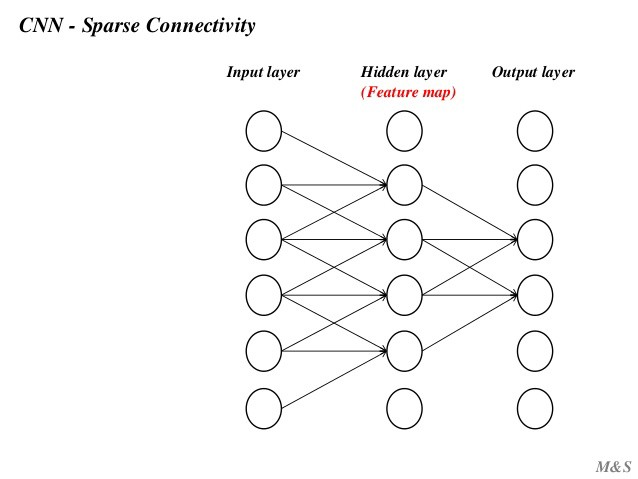
总的来说,使用稀疏连接方式能使网络储存更少的参数,降低模型的内存要求,同时提高计算效率。
在传统的神经网络中,每个元素都使用一个对应的参数(权重)进行学习。但是,在CNNs中卷积核参数是共享的。权值共享,也称为参数共享,是指在计算图层的输出时多次使用相同的参数进行卷积运算。
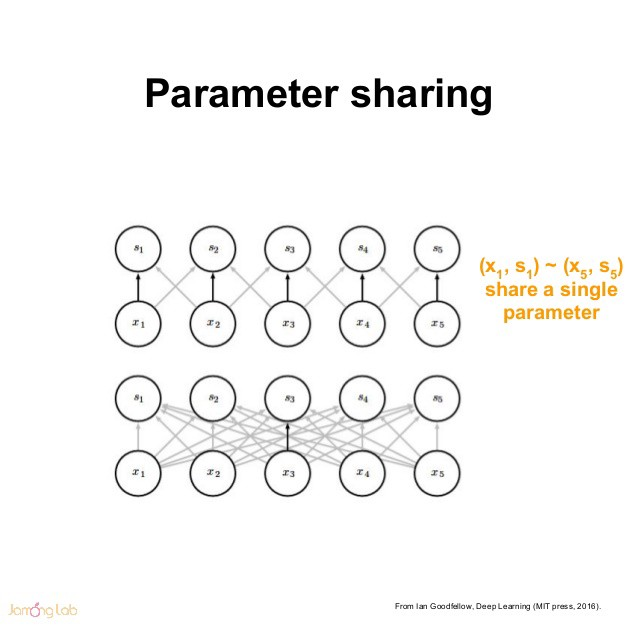
CNNs中的平移不变性指的是当图像中的目标发生偏移时网络仍然能够输出同源图像一致的结果。对于图像分类任务来说,我们大家都希望CNNs具备平移不变性,因为当图像中目标发生位置偏移时其输出结果应保持一致。然而,CNNs结构本身所带来的平移不变性是非常脆弱的,大多数时候还要从大量数据中学习出来。
CNNs中的平移等变性指的是当输入发生偏移时网络的输出结果也应该发生相应的偏移。这种特性比较适用于目标检测和语义分割等任务。CNNs中卷积操作的参数共享使得它对平移操作具有等变性,而一些池化操作对平移有近似不变性。
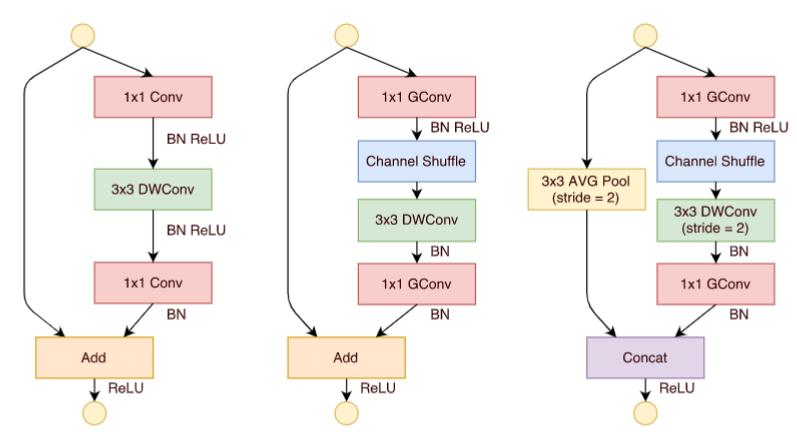
受单个GPU算力的瓶颈限制,组卷积在早期阶段是被应用于切分网络使其能够在多个GPU上进行并行计算,之后被大范围的应用到ResNeXt[2]网络中。
原始卷积操作中每一个输出通道都与输入的每一个通道相连接,通道之间是以稠密方式来进行连接。而组卷积中输入和输出的通道会被划分为多个组,每个组的输出通道只和对应组内的输入通道相连接,而与其它组的通道无关。这种分组(split)的思想随后被绝大多数的新晋卷积所应用。
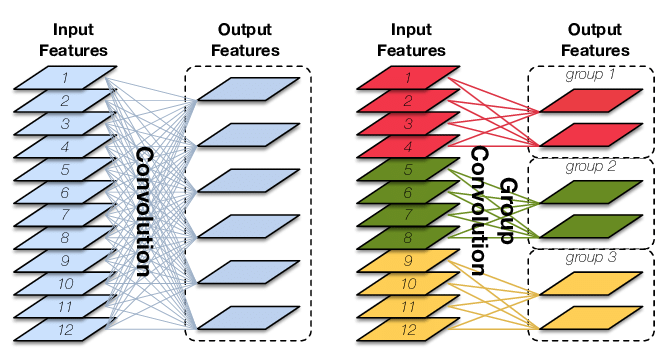
通过将卷积运算按通道划分为多个路径,可以尽可能地利用分布式的计算资源进行并行运算,有利于大规模深度神经网络的训练。
组卷积可以看成是对原始卷积操作的一种解耦,改善原始卷积操作中滤波器之间的稀疏性,在某些特定的程度上起到正则化的作用。
原始的组卷积实现中,不同通道的特征会被划分到不同的组里面,直到网络的末端才将其融合起来,中间过程显然缺乏信息的交互(考虑到不同滤波器可提取到不同的特征)。
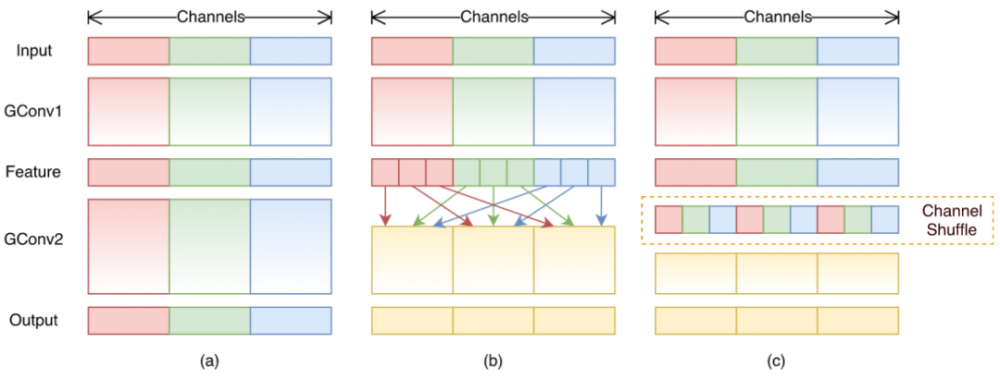
单纯地应用PGC虽能有效的降低计算复杂度,但同时也会引入副作用(组与组之间的信息无交互)。因此,作者进一步地应用通道混洗操作来促使信息更好的流通。最后,论文中也提出了一种Shuffle单元。
转置卷积,也称为反卷积(Deconvolution)或微步卷积(Fractionally-strided Convolution),一般应用在编解码结构中的****部分或者DCGAN中的生成器中等。但由于数字信号处理中也有反卷积的概念,所以一般为了不造成歧义,大多数框架的API都会定义为转置卷积。
与常规的卷积操作不同,转置卷积是一种一对多的映射关系,即输入矩阵中的一个值映射到输出矩阵的K×K(i.e., kernel size)个值。在具体的实现当中,需要维护一个转置矩阵,这个矩阵参数是可学习的。
利用转置卷积,可以引入参数让网络自动学习卷积核的权重以更好地恢复空间分辨率。一般来说,利用转置卷积来替代常规的上采样操作(最近邻插值、双线性插值即双立方插值)会取得更好的效果(在没有过拟合的情况下),弊端是增大了参数量,且容易出现网格效应[5]。
利用转置卷积还可以对特征图进行可视化。有时间的强烈推荐大家去阅读原论文《Visualizing and Understanding Convolutional Networks》[6],有助于帮助大家理解不同深度的各个特征图究竟学到了什么特征。比如,增加网络的深度有利于提取更加抽象的高级语义特征,而增加网络的宽度有利于增强特征多样性的表达。或者是小的卷积核有利于特征的学习,而小的步长则有利于保留更多的空间细节信息。
1×1卷积最初提出的目的是用于增强模型对特定感受野下的局部区域的判定能力。后续也被GoogleNet[8]和ResNet[9]进一步的应用。
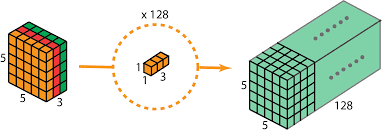
1×1卷积本质上也是一个带参数的滤波器,在不改变特征图本身尺寸的情况下,能够增加网络深度。通过在卷积后通过非线性激活函数可以轻松又有效的增强网络的表达能力。
1×1卷积能够最终靠增加或减少滤波器的数量来实现升维或降维的目的。与全连接层不同,由于卷积是基于权值共享,因此可以有明显效果地的降低网络的参数量和计算量。另一方面,降低维度可以认为是通过减少冗余的特征图来降低模型中间层权重的稀疏性,从而得到一个更加紧凑的网络结构。
类似于多层感知机,1×1卷积本质上就是多个特征图之间的线卷积操作可以轻轻松松实现跨通道的信息交互和整合。
空洞卷积,也称为扩张卷积(Dilated Convolution),最早是针对语义分割任务所提出来的。由于语义分割是一种像素级的分类,经过编码器所提取出的高级特征图最终需要上采样到原始输入特征图的空间分辨率。因此,为了限制网络整体的计算效率,通常会采用池化和插值等上/下采样操作,但这对语义分割这种稠密预测任务来说是非常致命的,大多数表现在以下三方面:
不可学习:由于上采样操作(如双线性插值法)是固定的即不可学习的,所以并不能重建回原始的空间信息。
损失空间信息:引入池化操作不可避免的会导致内部数据结构丢失,导致空间细节信息严重丢失。
丢失小目标:经过N次池化(每次下采样2倍),原则上小于个像素点的目标信息将不可重建,这对于语义分割这种密集型预测任务来说是致命的。
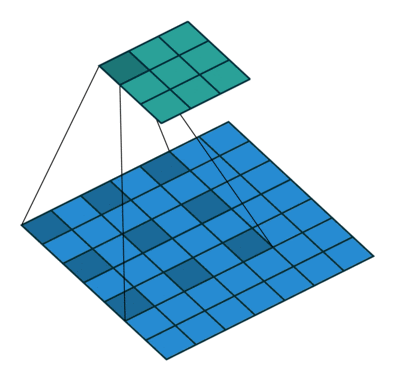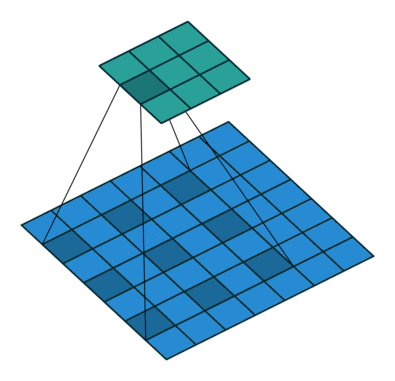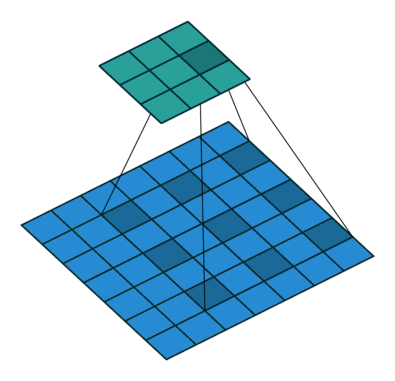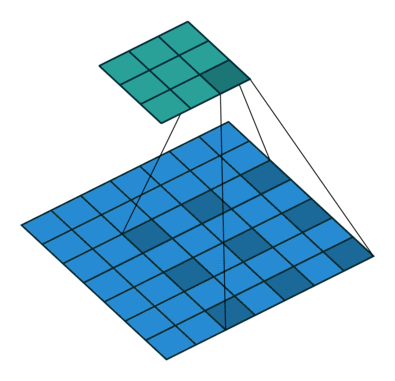
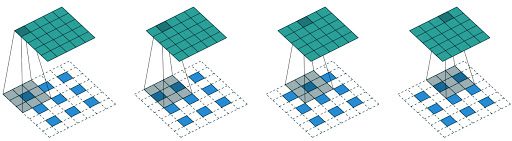
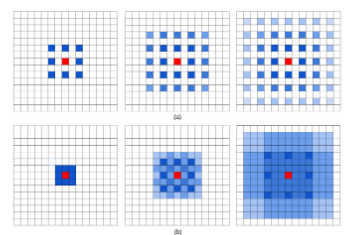
空洞卷积可看成是原始卷积更进一步的扩展,通过在原始卷积的基础上引入空洞率这个超参数,用于调节卷积核的间隔数量。比如,原始卷积核其空洞率为1,而对于空洞率为k的卷积则用0去填充空白的区域。
空洞卷积可以在同等卷积核参数下获得更大的感受野。所以,对需要较为全局的语义信息或类似于语音文本需要较长的序列信息依赖的任务中,都能够尝试应用空洞卷积。
利用带有不同空洞率的卷积,还可以捕捉到多尺度的上下文语义信息。不同的空洞率代表着不同的感受野,意味着网络能够感知到不一样的尺寸的目标。
虽然引入空洞卷积可以在参数不变的情况增大感受野,但是由于空间分辨率的增大,所以在实际中常常会不好优化,速度方面是一个诟病,因此在工业上对实时性有要求的应用更多的还是类FCN结构。
应用空洞卷积也引入网格效应。由图森和谷歌大脑合作研究的《Understanding Convolution for Semantic Segmentation》[11]文章指出了如果多次使用空洞率相同的卷积去提取特征时会损失掉信息的连续性。这是因为卷积核并不连续,导致许多的像素从头到尾都没有参与到运算当中,相当于失效了,这对于语义分割这类的密集型预测任务来说是十分不友好的,特别是针对小目标来说。一个解决方案是令所叠加的卷积其空洞率不能出现大于1的公约数,如令其等于[1, 2, 5],使其呈现锯齿结构。
*博客内容为网友个人发布,仅代表博主个人自己的观点,如有侵权请联系工作人员删除。
Copyright © 2012-2020 mile米乐m6官网入口(官方)网站IOS/Android通用版/手机app 版权所有 沪ICP备2020030748号-2
地址:上海青浦区虹桥世界中心B栋355室 电话:400-630-8958 邮箱:sales@infusetek.com.cn

关注我们